
【新唐人北京时间2023年11月17日讯】近日,网友实测了ChatGPT、文心一言看图说话的能力,结论是:一个可以称智商,一个是智障。
11月15日,微信公众号“Howie和小能熊”发文说,受网友启发,决定让ChatGPT和各个大模型一起来看图说话,横向对比下大模型的能力。
文章说,选取的图片不是随手拍照,而是漫画。漫画类图片是人类艺术家的创造性表达,经常有一些幽默、讽刺等微妙之意蕴含其中,需要一些理解能力才能解读。所以,测试的不只是“视力”,更是“智力”。
他用几幅图片,实测了美国ChatGPT和中国大陆百度开发的“文心一言”的看图说话能力。结果如下:
第一张图是《New Yorker》杂志最新一期封面:

作者说,ChatGPT的回答“内容描述准确无错误,理解到位且无错误”。

而文心一言的回答“充满了错误和幻觉,胡说八道的实例。你家小孩写看图作文写成这样,也就是0分了”。

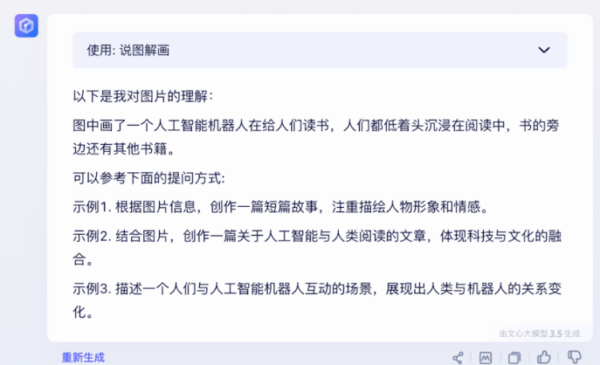
第二幅图,名为“人类沉迷,机器学习”(Humans are hooked, machines are learning)。

作者评价,ChatGPT的答案“描述上有错,把长椅说成了课桌,理解上,GPT强调沉迷手机的人类忽视了外部环境和培养成长和创造力的活动,沉浸于数字世界。很棒!”

而文心一言的回答“描述上胡言乱语,理解上乱七八糟。横批:什么玩意”。
第三张图片,是Peanuts漫画“Born to Sleep”(天生喜欢睡觉)。

作者评价说,ChatGPT“描述ok,还提供了人物的作者信息,可见世界知识很全。理解上,还脑补了snoopy的内心活动,不错!”

而文心一言“描述上大量错误,胡说八道。理解肤浅”。

作者还测试了其它实例,最后表示,自己之前认为两者存在几倍差距(1倍以上、10倍以下),但是现在发现,用数量差距、百分比、倍数来评价这些结果差异是不合适的。因为本质上不是数量差距,而是性质差距。无论是差2倍还是5倍,实际上都是不及格,都是不能用,对真实用户的真实使用场景没区别,都没意义。
所以,更准确的说法:这是 “能用”和“不能用”的差距。所谓“能用”,就是能用来取代你的部分任务,可以整合到你的工作流;而不能用,就是不能啊。
作者说,一个“不能用”的AI,看起来一本正经,甚至“不明觉厉”,但是,与真正的智能,还是有一字之别。
(责任编辑:李郦)

























